


Introduction : hypothèses, obstacles, originalité
Le projet IThAC1 a pour objectif l’étude de la réception du théâtre antique en Europe au XVIe siècle à travers l’analyse du corpus des paratextes savants imprimés qui lui sont consacrés, et la mise à disposition de la communauté scientifique de la traduction de ce corpus traduit en français, grâce à la construction d’une interface numérique évolutive. Par « paratextes savants du XVIe siècle », on entend les textes liminaires – épîtres dédicatoires, adresses au lecteur, préfaces, Vies, traités théoriques rédigés par des humanistes au XVIe siècle. Les textes étudiés s’étendent de la période comprise entre 1476, date de la parution de la première édition imprimée de Térence dotée d’un paratexte, au début du XVIIe siècle.
On fait l’hypothèse que la collecte, la traduction et l’analyse de ce corpus, longtemps négligé parce que difficilement accessible matériellement et parce que très largement rédigé en latin, permet de saisir à la fois comment le théâtre antique a été reçu et compris par ses « inventeurs » dans l’Europe du XVIe siècle, mais aussi comment les idées et les méthodes formulées dans et véhiculées par ce corpus, à l’heure où s’inventaient aussi bien le théâtre moderne que la philologie, ont circulé et se sont développées grâce notamment à leur large diffusion rendue possible par l’imprimé. C’est aux éditions qui ont assuré cette diffusion que nous nous intéressons ; le corpus ne prend donc pas en compte des exemplaires particuliers annotés ni des manuscrits, dont l’intérêt est certain mais qui relèveraient d’un autre projet. Ces paratextes, qui sont souvent le fait de très grands savants, ont connu en leur temps une audience et une circulation bien plus importantes que celles des textes rédigés en vernaculaire, parce que le latin était alors la langue de la communication savante : les négliger, c’est omettre une étape majeure des débats intellectuels sur le théâtre, la philologie et la transmission et la réception de l’Antiquité, débats que leur prise en considération permet de reconstruire, en redonnant leur place à des figures majeures comme Melanchthon, Camerarius, Scaliger et autre Casaubon, en faisant émerger des figures de moindre envergure – professeurs, traducteurs, imprimeurs, libraires – qui ont également joué un rôle clé dans l’élaboration et la circulation de ces idées, et en mettant en lumière grâce à l’outil numérique cette élaboration et cette circulation.
L’obstacle majeur à la prise en compte de ce corpus a longtemps été celui de son accessibilité ; grâce au développement de la numérisation et aux campagnes systématiques de mise à disposition numérique menées par différentes institutions, il est désormais plus facile d’accès, mais il reste des éditions qui ne sont pas encore numérisées, voire repérées.
Le deuxième obstacle à l’étude de ce corpus de paratextes est qu’il est très majoritairement rédigé en latin, parfois aussi en grec, et que la connaissance de ces deux langues tend à diminuer aussi bien parmi les chercheurs en littératures modernes que parmi les étudiants.
Le troisième obstacle est lié aux champs disciplinaires : les spécialistes du théâtre antique ne s’intéressent d’ordinaire pas à cette période de la transmission des textes dramatiques anciens, privilégiant soit l’étude de leur transmission manuscrite, soit leur réception contemporaine ; quant aux spécialistes des théâtres du XVIe siècle, ils donnent la priorité à l’étude des théâtres en vernaculaire ou en néo-latin plutôt qu’à celle des textes savants accompagnant les éditions du théâtre antique.
Le quatrième obstacle tient au fait que les rares spécialistes des poètes dramatiques antiques qui s’intéressent à la réception de ces textes au XVIe siècle concentrent leurs travaux sur un poète, sans le mettre en relation avec ce qui se dit des autres poètes dramatiques ni mettre en relation les poètes grecs et les poètes latins.
La réunion au sein du projet de spécialistes de ces différents domaines, la traduction et la construction d’une interface numérique permettant d’explorer l’intégralité de ce corpus a permis de surmonter ces obstacles et de contribuer, tout d’abord, à la diffusion d’un corpus essentiel à la compréhension de l’histoire du théâtre antique et du théâtre occidental depuis la Renaissance. Mais au-delà de la diffusion du corpus collecté, traduit et transcrit, on a surtout mis en relation cet important ensemble de textes très rarement étudiés et plus rarement encore mis en relation, grâce à l’outil numérique. On a ainsi fait émerger des concepts, des figures, des réseaux, des lieux clés de l’invention du théâtre antique. Qui plus est, les outils numériques d’analyse développés dans le cadre du projet IThAC pourront être réutilisés et servir à d’autres projets d’analyse à grande échelle de corpus de textes patrimoniaux. En effet, par-delà la micro-analyse des textes du corpus, c’est la lecture distante, au sens où l’entend Franco Moretti (Moretti 2005) que l’on compte ici promouvoir dans l’analyse de ces textes, avec l’idée qu’elle offre l’opportunité de renouveler en profondeur l’idée que l’on s’est faite, et que l’on se fait aujourd’hui, de différents corpus, dont celui du théâtre antique.
Le caractère novateur du projet IThAC tient ainsi au fait qu’il a traité un corpus peu ou pas étudié car à l’articulation de plusieurs champs, mais essentiel du point de vue de la réception du théâtre antique, de l’histoire du théâtre occidental et plus largement de la transmission d’un héritage intellectuel négligé. L’originalité du projet IThAC tient également à la méthodologie adoptée, qui consiste en la réunion d’une équipe pluridisciplinaire et pluri-compétente, à savoir des spécialistes des poètes dramatiques grecs et latins, des spécialistes du théâtre néo-latin et des théâtres en vernaculaire du XVIe siècle, des spécialistes de la Renaissance et des spécialistes de l’édition et de l’exploration numérique des textes patrimoniaux.
Seule cette réunion de compétences était en effet à même de traiter un tel corpus et d’aboutir non seulement à la description, la localisation et la mise à disposition de ce très large corpus traduit, mais aussi à son analyse transversale.
Les outils d’exploration numériques développés permettent en effet de mettre en relation les textes du corpus, pour faire émerger les concepts-clés du discours critique, la périodisation de leur émergence, l’évolution du nombre d’éditions par auteur, par langue, par pays ; la cartographie des lieux d’édition ; les réseaux d’humanistes et la circulation des idées. Le projet IThAC est donc novateur aussi bien du point de vue du corpus traité que des méthodologies adoptées et de l’équipe qu’il réunit pour le traiter.
État de la question
Ce corpus n’avait pas encore fait l’objet d’une étude systématique. Un travail de ce type avait cependant été mené sur un corpus proche grâce au projet ANR Les Idées du Théâtre (IdT) sur les paratextes des théâtres en vernaculaire de l’Europe de la Première modernité, qui a révélé l’importance de ces textes dans l’élaboration des théories du théâtre moderne. Un autre travail en partie similaire, de traduction systématique des théories poétiques de la Renaissance rédigées en néo-latin, avait été mené par Virginie Leroux, Émilie Séris et toute une équipe de traductrices. Mais si le corpus envisagé était rédigé en latin, il ne prenait que marginalement en compte les paratextes savants ; surtout, la place accordée au théâtre y était particulièrement réduite, le théâtre antique quasiment absent.
En ce qui concerne le corpus de la réception du théâtre antique à la Renaissance, on disposait essentiellement de travaux portant sur un auteur donné. Monique Mund-Döpchie a recensé et commenté les éditions d’Eschyle à la Renaissance et Elia Borza celles de Sophocle en Italie ; Patrick Hadley s’est intéressé à la lecture d’Aristophane par l’érudit allemand Frischlin à travers les paratextes latins de son édition du poète comique (1586). Mais ces travaux, consacrés chacun à un poète dramatique, tout précieux qu’ils soient, demandaient à être complétés et systématisés du point de vue de la collecte et de la traduction des paratextes, et à être mis en relation.
Il existait enfin quelques outils numériques qui ont été spécifiquement élaborés pour le traitement numérique des données liées à la réception du théâtre antique : Hyperdonat, piloté par Christian Nicolas, et L’Aristophane de Lobineau, piloté par Malika Bastin-Hammou, avec la collaboration d’Anne Garcia Fernandez, Elisabeth Greslou et Arnaud Bey. Mais le projet IThAC ambitionnait plus que la simple édition numérique d’un corpus traduit : il s’est attelé à développer des outils d’explorations spécifiques au corpus.
Méthodologie et traitement des données
Le travail a été mené par une équipe de chercheurs et d’ingénieurs de recherche permanents ainsi que par une post-doctorante, des doctorantes, des contractuels et des stagiaires, dont les noms et les tâches sont mentionnés dans les métadonnées des fichiers TEI et peuvent être consultés sur le site.
Repérage, numérisation et mise à disposition du corpus
Chaque fichier a été nommé selon un protocole identique : le nom de l’auteur abrégé, la date du paratexte, l’auteur du paratexte dans sa version latine, le numéro du paratexte parmi les paratextes de l’auteur dans l’édition concernée. Ainsi, Ar1589_Christianus_p2 renvoie au deuxième paratexte de Florent Chrestien dans l’édition d’Aristophane de 1589.
Ces fiches sont déposées sur le Cloud de l’UGA dans un dossier Corpus, qui contient 7 dossiers, un pour chacun des auteurs anciens du corpus (Eschyle, Sophocle, Euripide, Aristophane, Plaute, Térence, Sénèque).
Transcription et traduction
Ces paratextes ont été ensuite été transcrits et traduits lors de séminaire hebdomadaires pendant deux ans. C’est le format Word qui a été choisi, parce que c’est celui que maîtrisaient le mieux les chercheurs chargés de la transcription et de la traduction du corpus. Une fiche-type a été établie, identique pour tous, nommée avec l’identifiant du paratexte; elle contient 0. le nom des contributeurs 1.les métadonnées du paratexte (titre, auteur, destinataire, colophon, lieu, date, langue) 2. les métadonnées de la source (exemplaire, texte de la page de titre, auteur ancien, lieu de publication, date, imprimeur, éditeur, traducteur, type de texte) 3. des références bibliographiques 4. des remarques 5. le cas échéant, un lien vers une édition numérisée en libre accès. 6. Un tableau de saisie avec quatre colonnes, la première indiquant les numéros de phrases, la phrase ayant été choisie comme unité de base, la deuxième le texte latin, la troisième sa traduction, la quatrième d’éventuelles remarques.
Ces fichiers Word ont été déposés sur le Cloud de l’UGA dans un dossier Transcriptions & Traductions, qui contient 7 dossiers, un pour chacun des auteurs anciens du corpus.
Encodage en XML-TEI
Ces données ont ensuite été encodées en XML-TEI avec le logiciel Oxygen.
Un manuel d’encodage a été élaboré et déposé sur le Cloud, conforme aux guidelines du consortium TEI.
Le transfert des fichiers Word aux fichiers TEI a été fait manuellement.
Un programme a été créé pour automatiser la génération de tableaux contenant les identifiants des textes et de leurs traductions
Des menus déroulants fermés ont été créés pour les noms de personnes et pour l’étiquetage sémantique. Une liste fixe de dix balises a été créée : philologie, traduction, métrique, rhétorique du paratexte, pédagogie, religion, théâtre, histoire du livre et de l’imprimerie, argument, vie.
Tous les fichiers TEI ont été déposés sur le Cloud dans un dossier dédié et en ils sont en open access sur le site de consultation.
Ce schéma comprend des métadonnées « moissonnables » et un header qui synthétise les données relatives au corpus et à son exploitation.
Visualisation
La visualisation des données a été pensée en deux temps : d’abord sur un site accessible au public sur inscription puis sur un site public accessible à tous.
Ce site, nommé Pensoir (Φροντιστήριον, d’après les Nuées d’Aristophane) a été conçu comme un laboratoire numérique permettant aux membres du consortium de visualiser l’intégralité des textes transcrits et de leurs traductions.

L’arborescence a été pensée, conformément au projet, à partir des auteurs anciens dont il s’agit d’étudier la réception. L’entrée se fait donc à partir des sept auteurs dramatiques (trois latins, quatre grecs).
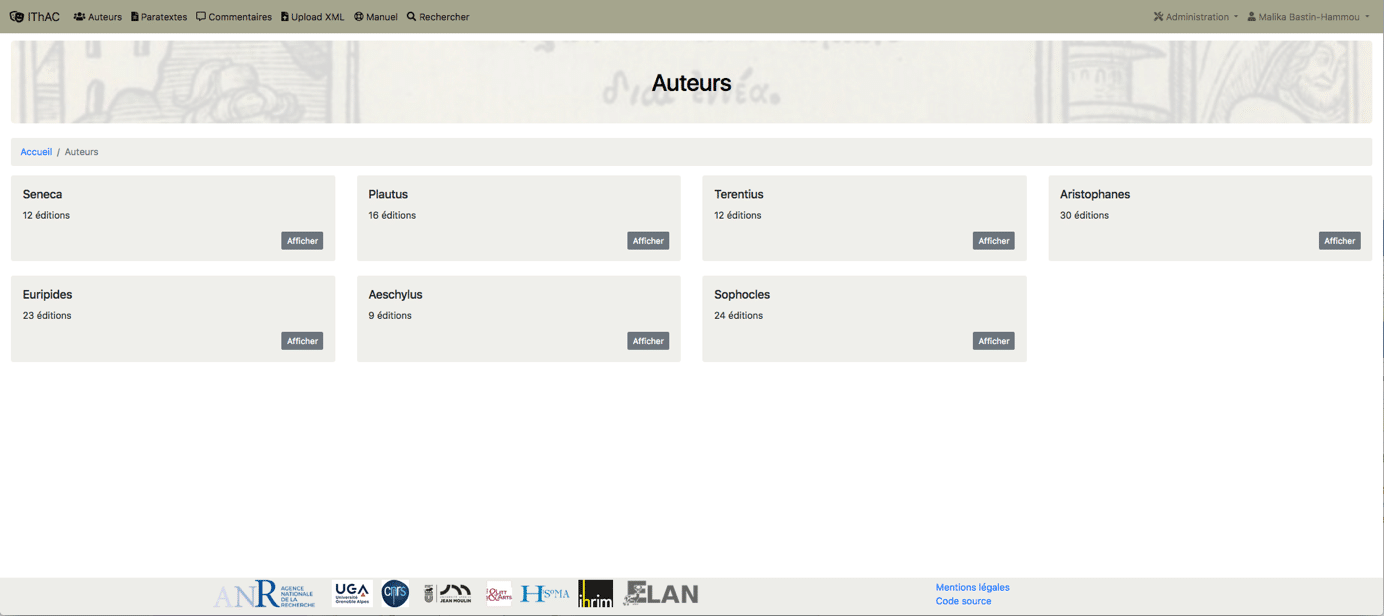
Pour chaque auteur antique on accède ensuite à l’ensemble des paratextes des éditions du corpus qui lui sont consacrés, par ordre chronologique.
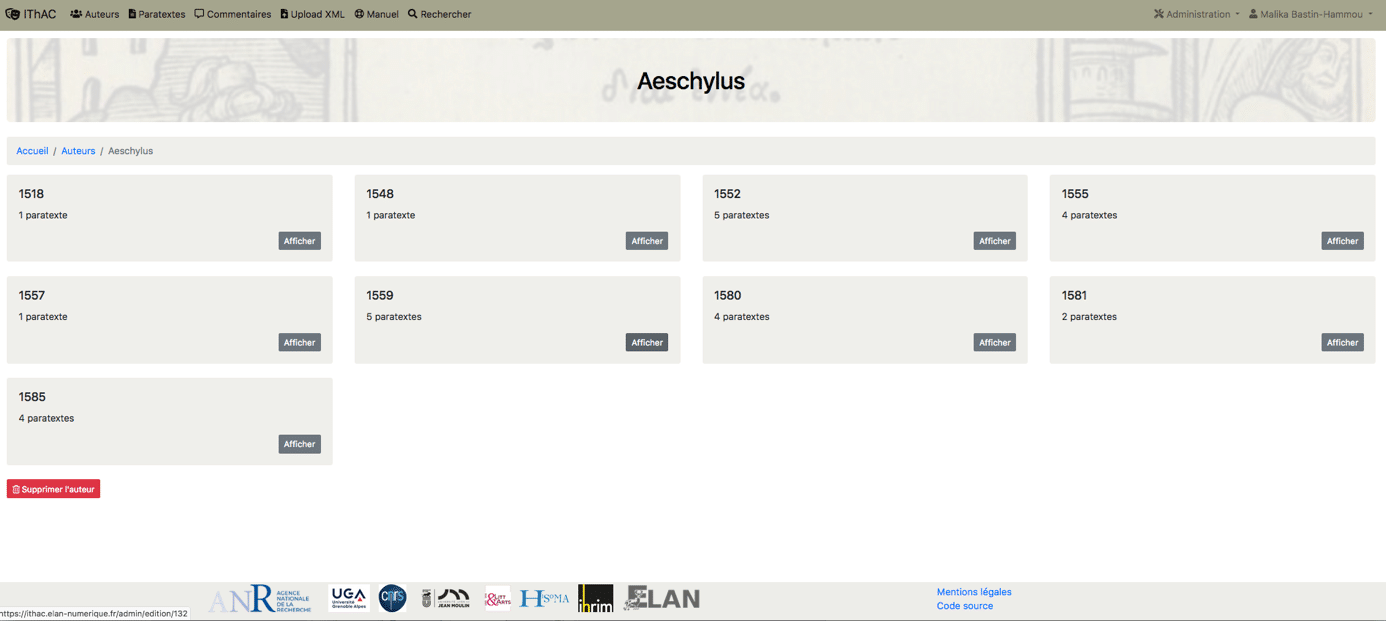
Chaque paratexte est présenté en deux colonnes parallèles, avec à gauche le texte original et à droite la traduction. Le paratexte est précédé des métadonnées suivantes : la source, une présentation du paratexte.
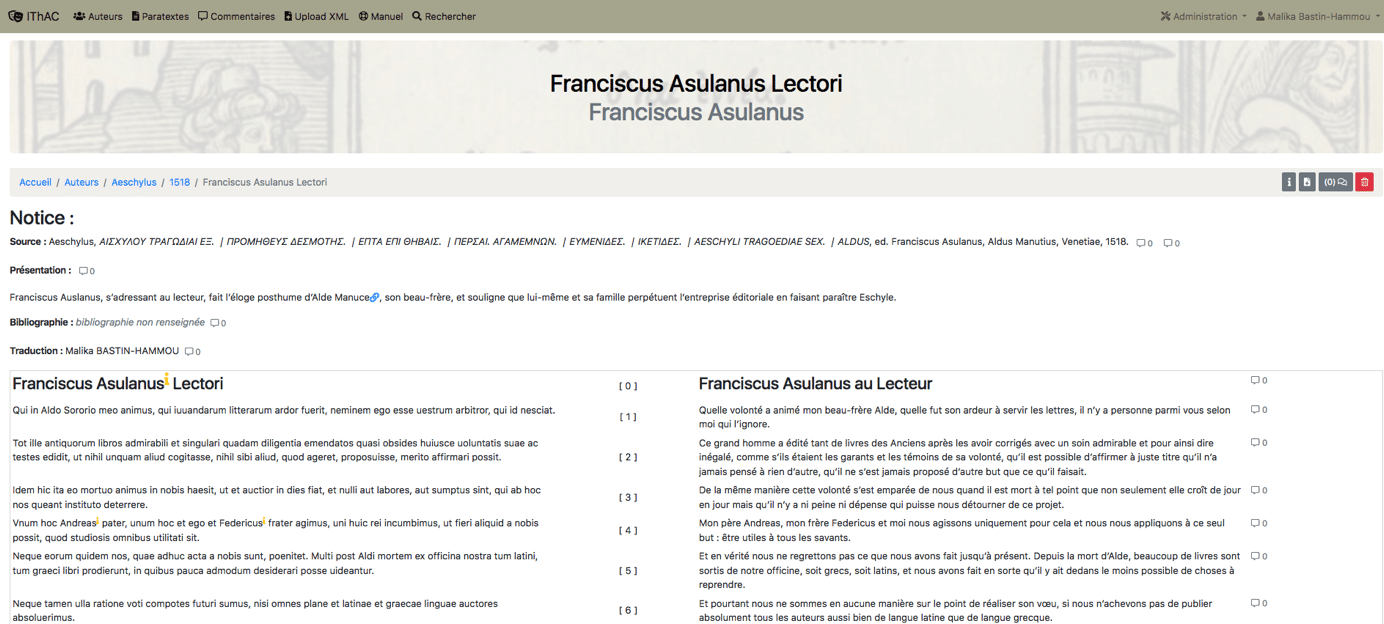
L’interface est dotée d’une fonction « commentaire » qui permet à quiconque souhaite faire part de ses remarques à l’ensemble de la communauté de rédiger en marge des annotations, auxquelles il est possible de répondre. Une fois la discussion terminée, la discussion est supprimée.
Cette fonction est très utile pour les relectures et l’exploration croisée du corpus.
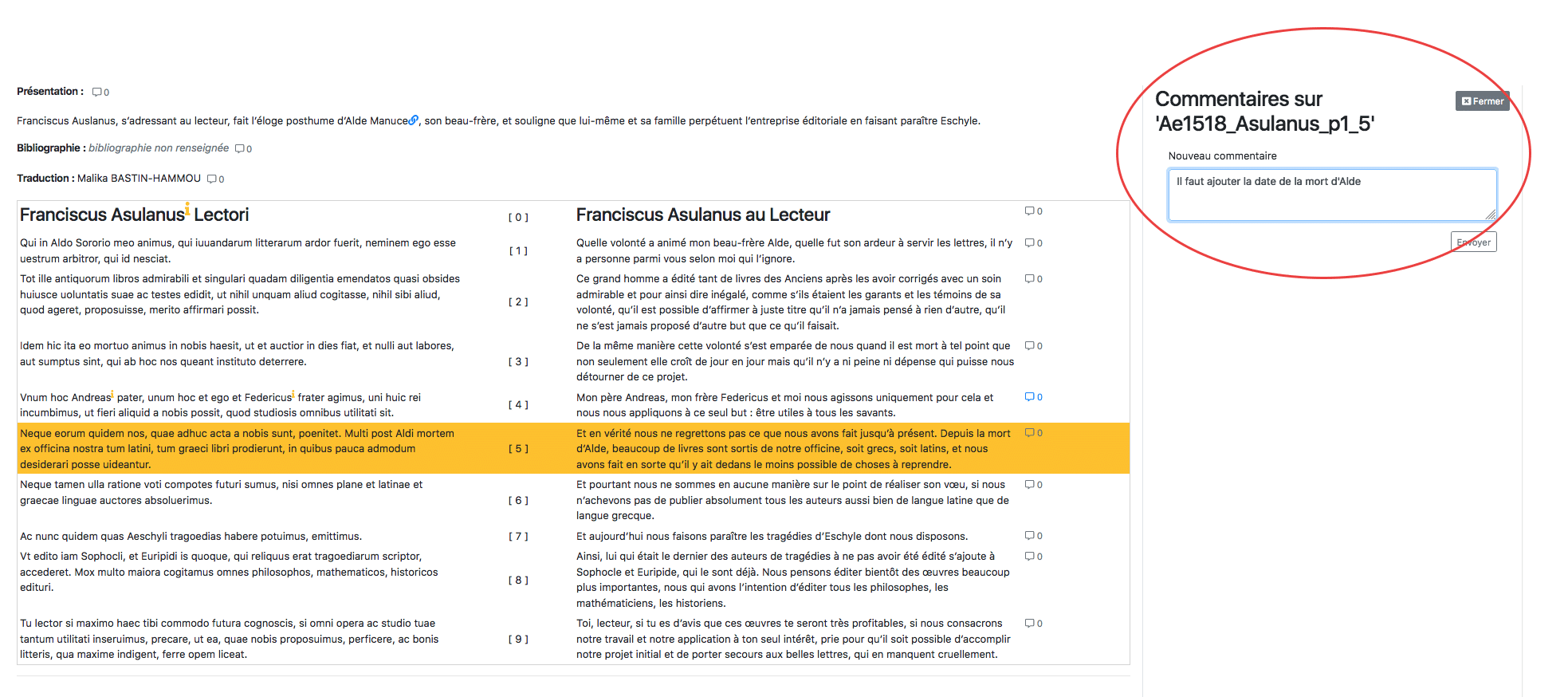
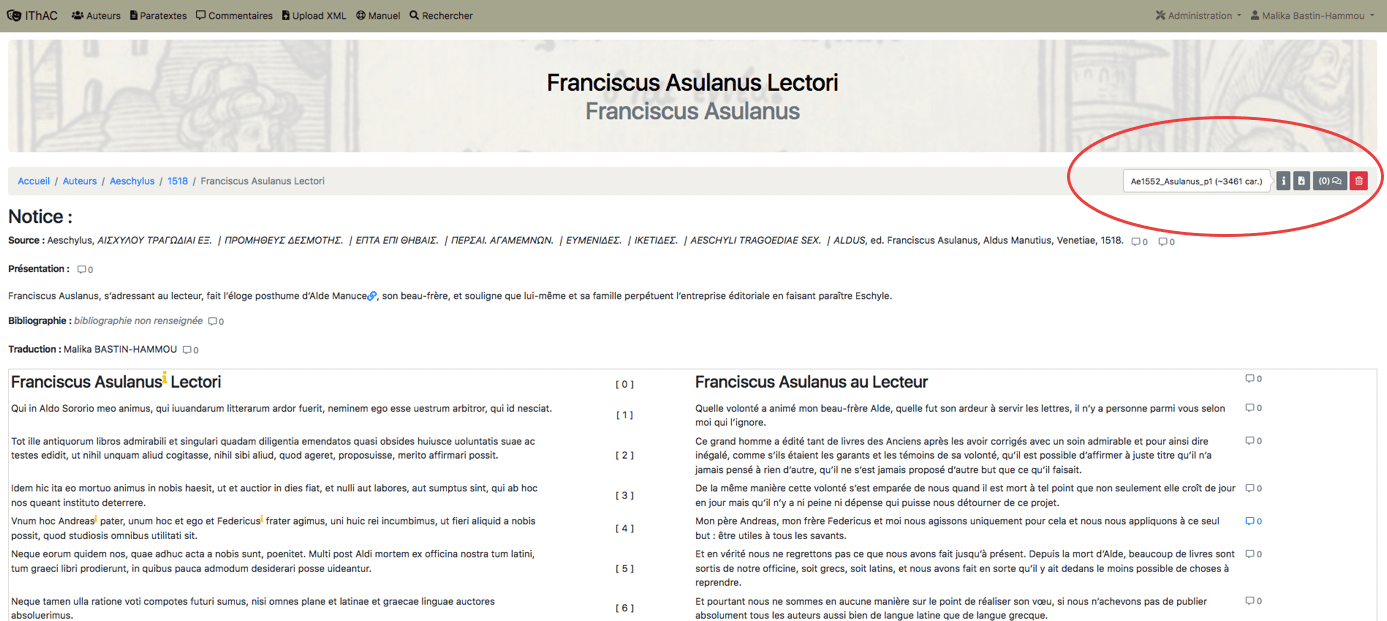
Un menu permet de connaître le nombre de caractères du paratexte, de télécharger le fichier TEI, de visualiser l’ensemble des commentaires et de supprimer la page.
Exploration
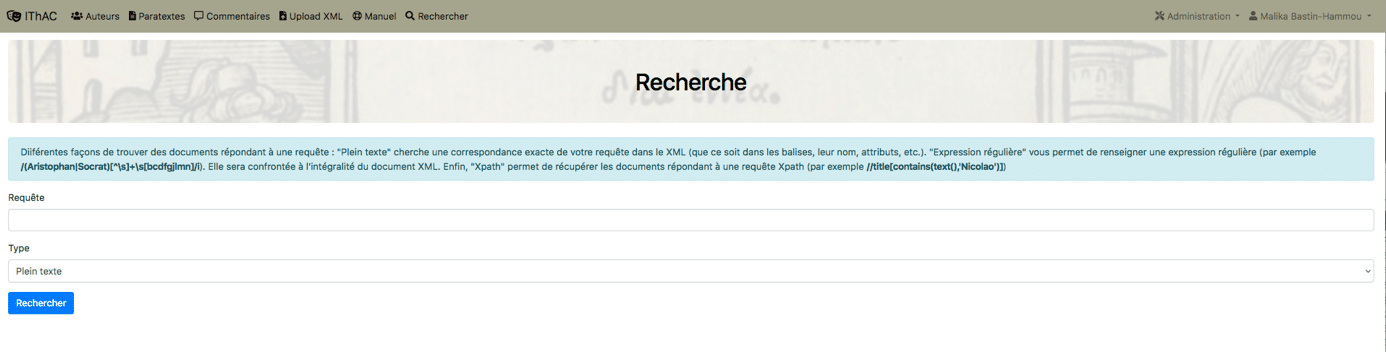
Le Pensoir permet également trois types d’exploration plus avancée : la recherche plein texte, la recherche d’expression régulière et la requête XPath.
À côté de ce laboratoire numérique, trois autres outils de visualisation et d’exploration ont été développés.
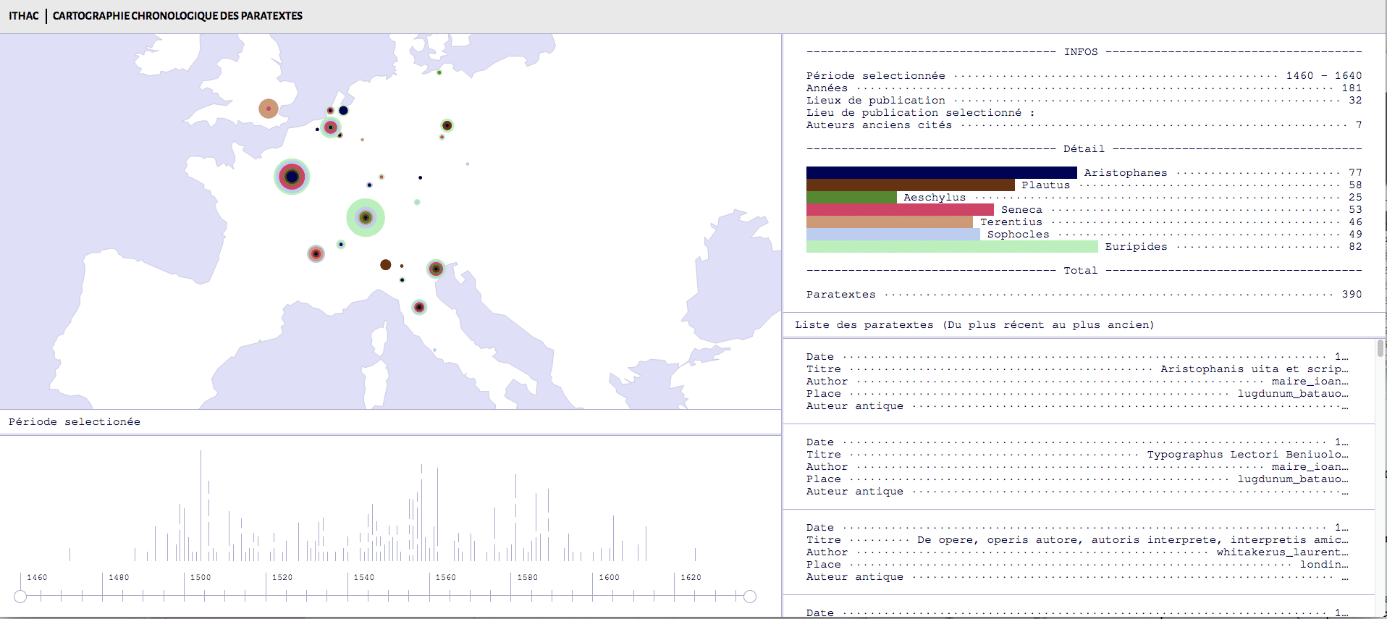
Tout d’abord, une carte dynamique permet de visualiser l’évolution au cours du XVIe siècle et dans l’espace européen de la production de paratextes, par auteur dramatique.
En bas, un curseur permet de sélectionner une période donnée et de voir, sur cette période, à quels auteurs sont consacrés des paratextes, et où.
Ensuite, l’interface XML-Explorer permet d’explorer les paratextes en croisant différents critères qu’il faut sélectionner dans un menu qui se trouve sur la gauche : langue du paratexte, auteur du paratexte, lieu de publication, imprimeur, éditeur, traducteur, analyse. Chacune de ces catégories peut alors être croisée avec une autre catégorie, ces dernières (« filtres ») proposant une liste à choix.
Ainsi, on peut croiser la catégorie « auteur » avec la catégorie « lieu de publication » avec le filtre « Bâle » : on obtient alors dix résultats, listés par auteur dans la colonne du milieu : deux paratextes à Eschyle, un à Euripide et dix à Sophocle. Dans la colonne de droite, on peut alors lire la date et le titre des paratextes concernés, par auteur.
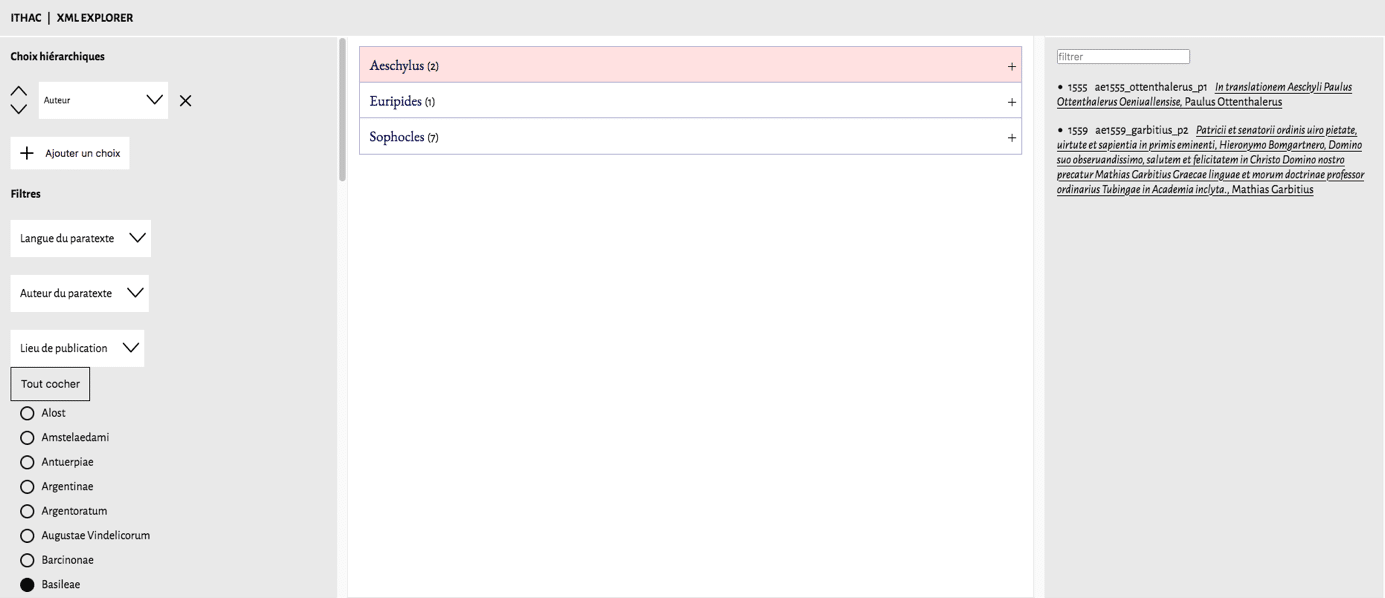
En cliquant sur ces titres, on obtient l’intégralité du paratexte transcrit et traduit avec ses métadonnées.

Les paratextes ainsi présentés sont également directement accessibles par liens hypertextes, du type https://ithac.elan-numerique.fr/p/Sq1488_Fernandus_p1 ce qui permet des renvois aisés depuis des travaux numériques : c’est le troisième outil.
Gestion des données et open access
Un plan de gestion des données a été élaboré au début du projet et mis à jour régulièrement, en recourant à la plateforme Opidor (https://dmp.opidor.fr/).
Les principes FAIR (Findable, Accessible, Interoperable, Re-usable) ont guidé le traitement des données. Les données ont été stockées sur le Cloud de l’UGA. Les fichiers TEI sont disponibles en open access sur les interfaces de visualisation. L’encodage a été fait selon les guidelines de la TEI et les données sont interopérables et réutilisables. À chacune des étapes, des tutoriels ont été rédigés à destination des utilisateurs et développeurs ; ils sont disponibles en open access sur l’interface de consultation, tout comme les sources de ladite interface. Les analyses issues des explorations numériques ayant fait l’objet de publications ont été déposées sur HAL et sont donc également en open access.
Conclusion : quelle répartition, quelle circulation, quelle complémentarité entre le papier et le numérique ?
Une des questions qui s’est posée est celle de la pertinence d’une diffusion papier en plus de la diffusion numérique. Quelles peuvent être les spécificités de chacune, comment peuvent-elles être complémentaires et comment éviter qu’elles ne fassent doublon ?
Il nous a semblé que l’édition numérique était le lieu de l’exploration des données et l’édition papier celle de la synthèse. Ainsi, l’édition papier se fera sous la forme d’une anthologie dont les chapitres thématiques seront précédés d’une synthèse, tandis que chaque paratexte imprimé sera précédé d’une introduction développée et orientée en fonction du chapitre dans lequel il se trouve. Un système de renvois permettra de circuler entre l’édition numérique et l’édition papier. L’avenir dira si cette répartition est pertinente.#
Bibliographie
- Bastin-Hammou Malika, Garcia Fernandez Anne et Greslou Elizabeth, L’Aristophane de Lobineau.
- Borza Elia, Sophocles redivivus. La survie de Sophocle en Italie au début du XVIe siècle. Éditions grecques, traductions latines et vernaculaires, Bari, Levante editori, 2007.
- Bureau Bruno, Nicolas Christian et Ingarao Maud, Hyperdonat.
- Hadley Patrick Lucky, Athens in Rome, Rome in Germany. Nicodemus Frischlin and the Rehabilitation of Aristophanes
in the 16th Century, Tubingue, Narr, 2015. - Jockers Matthew Lee, Macroanalysis. Digital Methods and Literary History, Chicago, University of Illinois Press, 2013.
- Moretti Franco, Graphs, Maps, Trees, Londres, Verso, 2005, trad. par Étienne Dobnesque sous le titre Graphes, cartes et arbres. Modèles abstraits pour une autre histoire de la littérature, Paris, Les Prairies ordinaires, 2008.
- Mund-Dopchie Monique, La survie d’Eschyle à la Renaissance, Louvain, Peeters, 1984.
- Nicolas Christian, « Nuptiae Philologiae et… X-Query », KOINΩNIA, Rivista dell’Associazione di Studi Tardoantichi, 38/2, 2014, p. 21-39.
- Pierazzo Elena, Digital scholarly editing: theories, models and methods, Farnham, Burlington, Ashgate, 2015.
- Vuillermoz Marc, Idées Du Théâtre.